
Two fundamental components of machine learning are labels and features, which are the backbones of machine learning.
Labels represent the desired outcomes or predictions we want to make, while features are the measurable characteristics or attributes of the data that help us make those predictions. Together, they form the foundation of training models and enable accurate predictions in various machine-learning tasks.
In This short article, we will delve into their significance and their roles in machine learning.
Labels
Labels, also known as the target variable or dependent variable, are the values we want to predict or classify in a machine learning task. They can be numerical (regression) or categorical (classification). In supervised learning, where a model is trained on labeled data, the labels are explicitly provided during the training phase. For example, in a spam email classification task, the labels would be "spam" or "not spam." The goal is to create a model that can accurately assign the correct label to new, unseen data.
Features
Features, also referred to as independent variables or predictors, are the measurable characteristics or attributes of the data that provide information to the machine learning model. These features are used to train the model and make predictions. Features can be numeric, categorical, or even text-based, depending on the type of data and the machine learning algorithm being used.
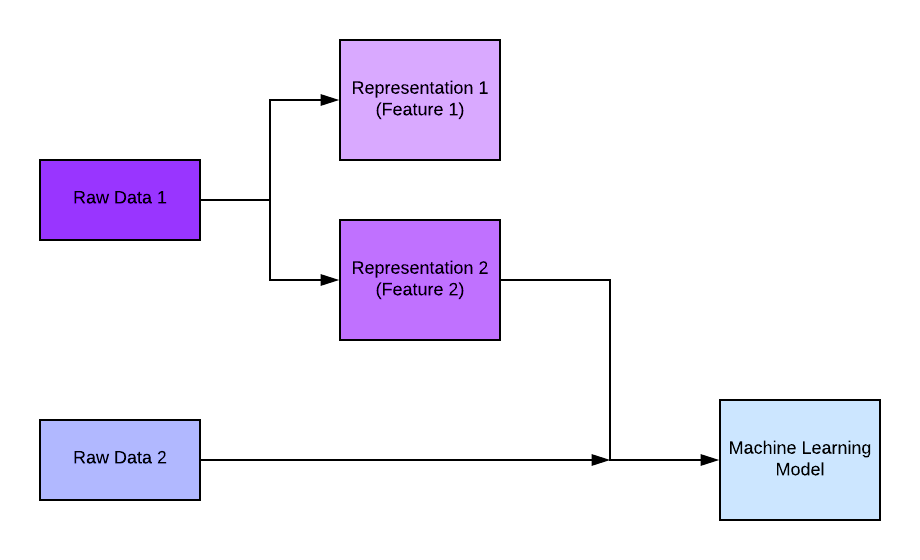
Feature engineering
Feature engineering is a critical step in machine learning, as it involves selecting and transforming the relevant features to improve the model's performance. This process may include techniques such as normalization, one-hot encoding, scaling, dimensionality reduction, or creating new features based on existing ones.
The relationship between labels and features is at the core of supervised machine learning. The model learns from the provided labeled data, extracting patterns and relationships between the features and the corresponding labels. By analyzing the features and their relationships to the labels, the model can make predictions on new, unseen data.
By understanding the relationship between labels and features, we can extract meaningful patterns from the data, train our models effectively, and make accurate predictions on new, unseen data. Careful consideration and thoughtful engineering of features are essential to ensure that the model captures the relevant information and generalizes well.